Main demo video
Coming soon
2026 May
University of Science and Technology of China
* Equal contribution. † Corresponding author.
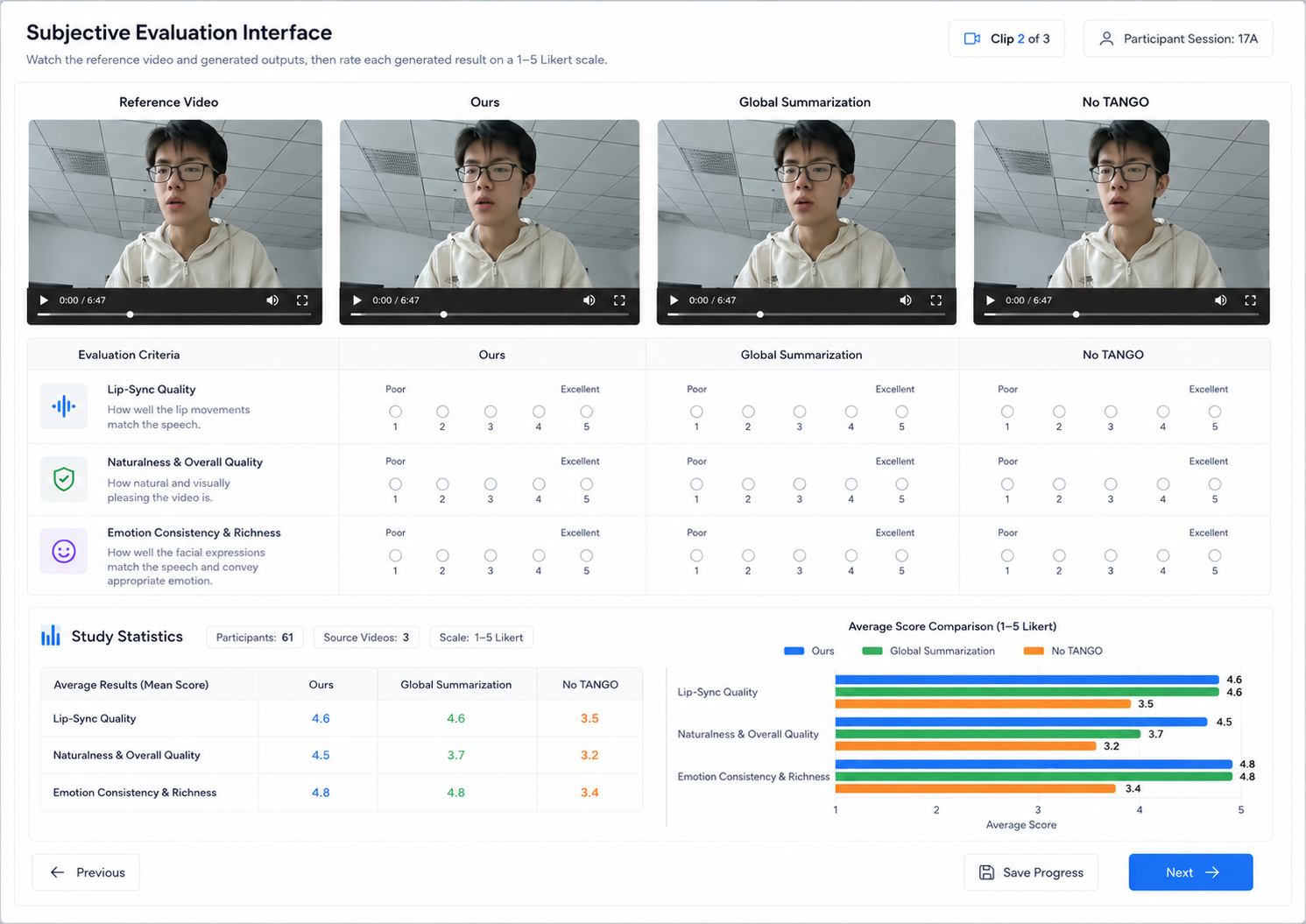
Demo and comparison videos are under preparation. The slots below are reserved for the main result video and related visual comparisons.
Coming soon
Coming soon
Coming soon
Coming soon
Coming soon
Long-form talking-head footage, including lectures, keynotes, interviews, and instructional content, carries dense knowledge, presentation rhythm, and affective trajectories expressed through speech prosody, facial dynamics, and body motion, yet is increasingly consumed in short-form formats.
We define long-form talking-head condensation as reducing duration while preserving linguistic content, affective trajectory, and on-camera performance continuity, so the source video's information and affective expression can be conveyed in less time. Existing text summarization and jump-cut summarization methods address only one side of this problem, while recent talking-head and digital-human synthesis methods do not directly solve interval selection, affect propagation, or cross-segment continuity.
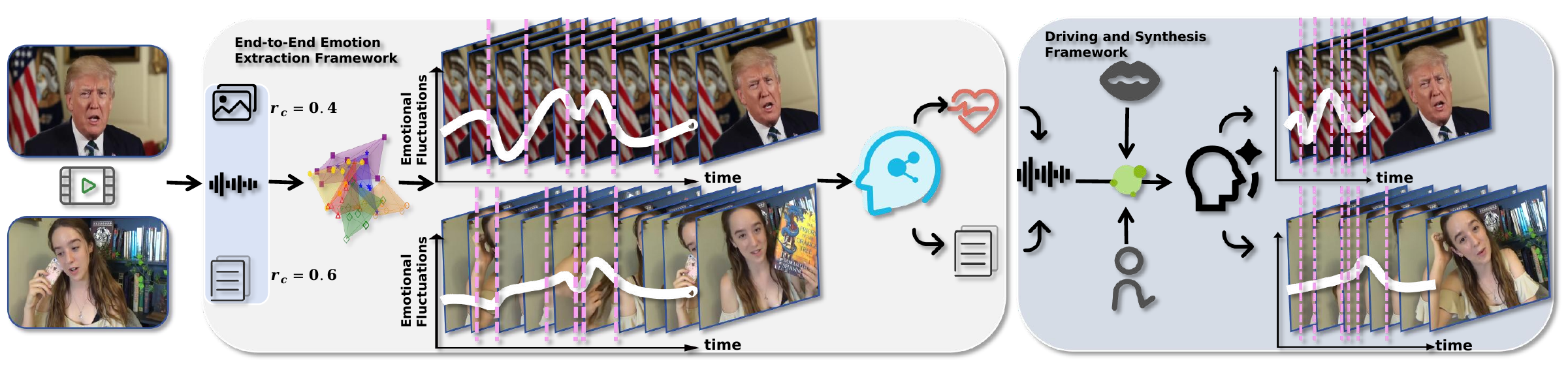
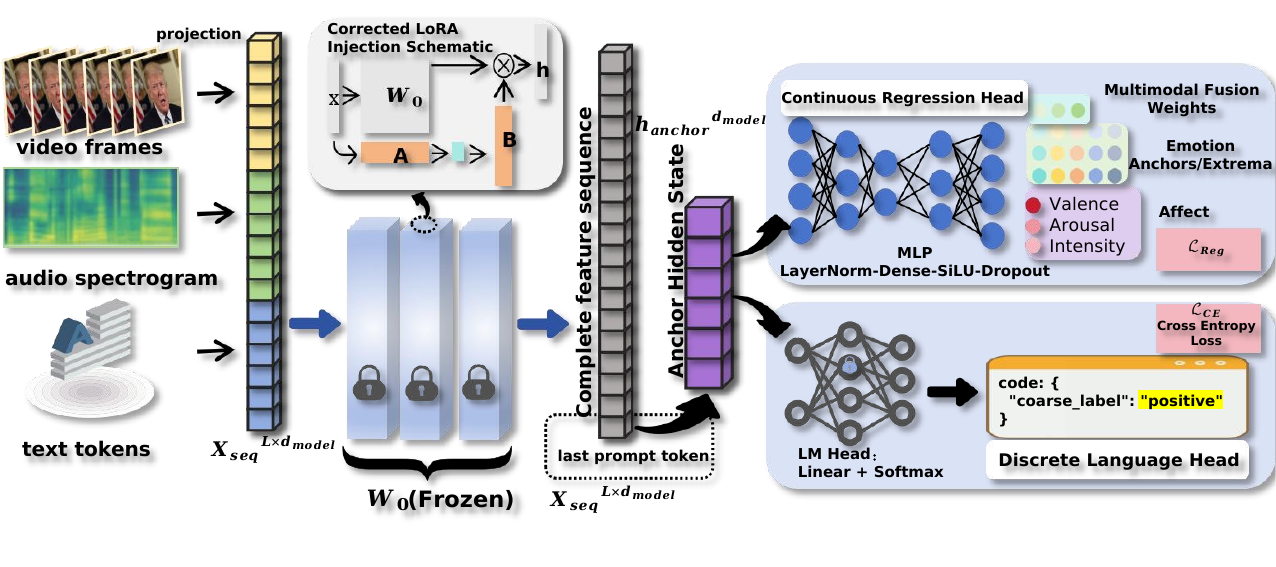
We present TalkSummary, a multimodal condensation-and-re-synthesis framework that renders long-form speech into a shorter, performance-preserving talking-head video under a user-specified compression ratio. TalkSummary segments the source by multimodal affective divergence, allocates compression budget with keyword priors and segment-level importance, predicts compressed transcripts and animation-ready Affective Control Packages, and drives voice, body motion, and lip synchronization with temporal smoothing.
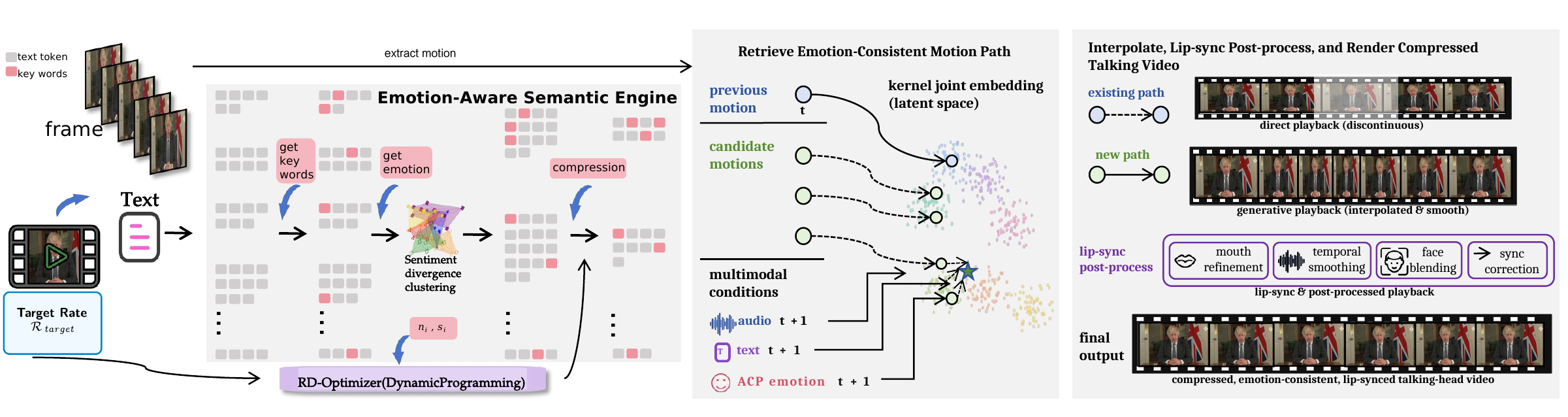
Text, audio, and visual channels are aligned to estimate semantic importance and affective dynamics across sentence-level segments.
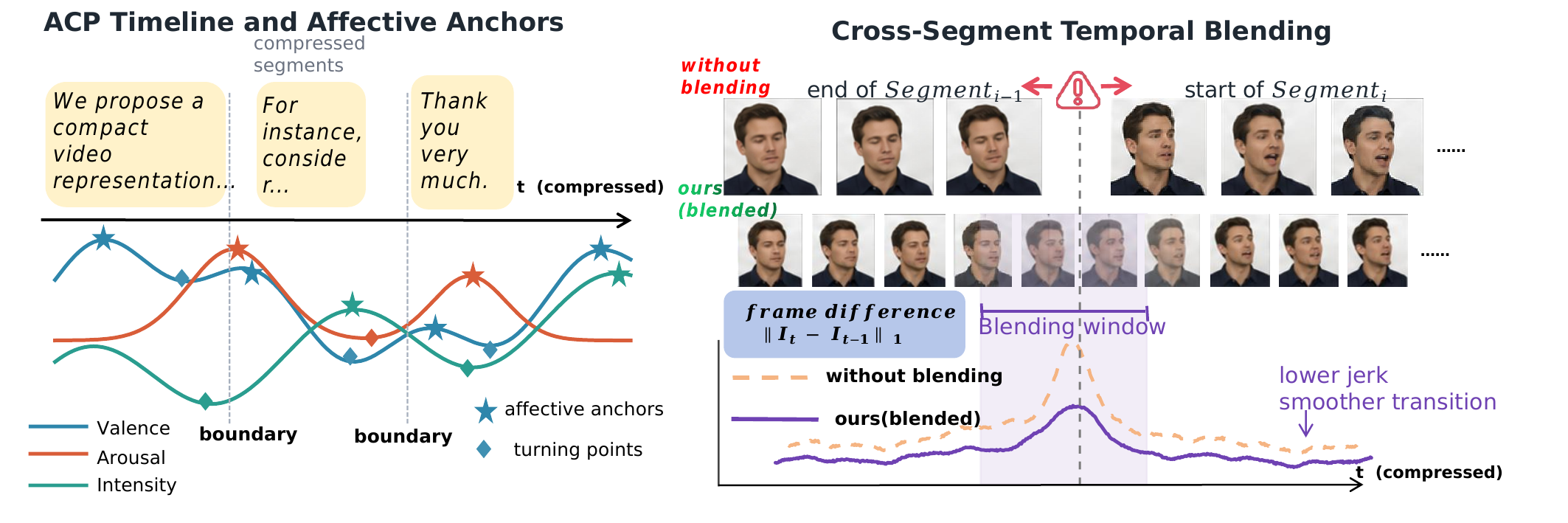
Dynamic programming allocates the target compression budget while retaining keyword priors and high-importance affective anchors.
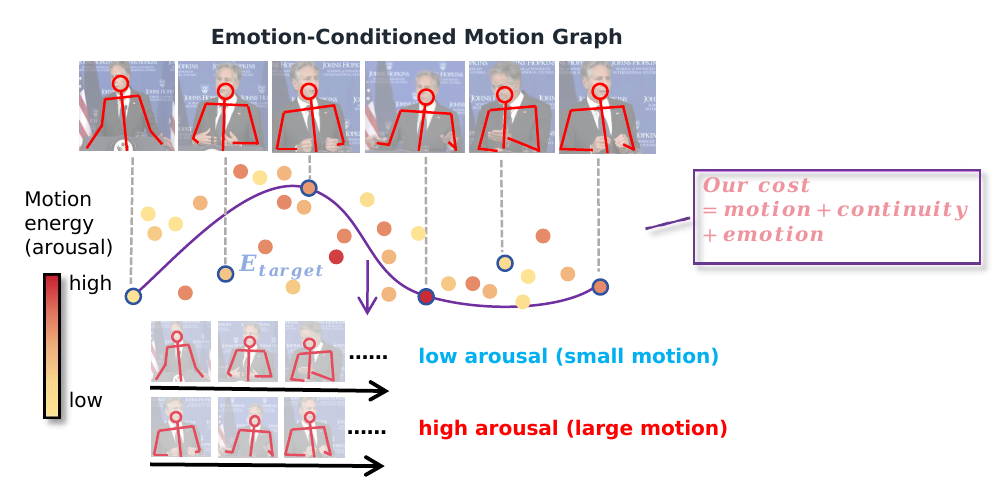
ACP signals guide voice cloning, emotion-conditioned body motion, lip synchronization, and boundary smoothing for continuous output video.

Coming soon
Coming soon
Coming soon